앞편에서는 체스와 체커라는 탐색과 보드 평가에 중심을 둔 AI 게임 플레이어의 구성에 관해 알아보았습니다. 이와 같은 설명은 기본적으로 바둑이나 장기 게임을 작성하는 경우에도 동일합니다. 그러나 체스나 체커와는 달리 바둑과 장기는 탐색해야 할 상태의 수가 현저하게 다릅니다. 체스와 장기를 비교하면 장기 쪽이 보드가 넓고 잡은 말을 다시 이용하는 등의 규칙상 특징이 있기 때문에 탐색해야 할 상태의 수가 더 많습니다.
바둑의 경우는 보드가 장기의 4배 이상인 데다 규칙이 단순한 만큼 착수가 자유로워 상태의 수가 매우 많아집니다. 더욱이 바둑의 경우는 어느 쪽 플레이어가 우수한지를 추정하는 평가가 어렵다는 특징이 있습니다. 여기서는 먼저 바둑에 관해 공부하고, 장기는 다음 편에서 공부하도록 하겠습니다.
우선 1장에서는 알파고 등장 이전의 바둑 플레이를 개괄적으로 알아본 후 알파고를 비롯한 이후의 일련의 연구 성과에 대해 공부합니다.
1. 알파고(AlphaGo) 이전의 AI 바둑 플레이어
1.1 1960 ~ 2005년: 탐색과 휴리스틱 평가함수
AI 바둑 플레이어의 연구가 시작된 1960년대 이래 21세기 초까지는 체스나 장기의 경우와 마찬가지로 AI 바둑 프로그램도 데이터베이스를 기반으로 최선의 착수점을 찾는 탐색기술을 중심으로 구성되었습니다. 즉 착수 가능한 수를 가능한 만큼 탐색하고 어느 정도의 탐색 범위에서 중단해서 얻은 보드의 평가에 근거해 착수를 결정했습니다. 그러나 바둑은 체스나 장기와 비교해 규칙상 허용이 되는 착수 가능한 탐색 범위가 상당히 넓다는 어려운 문제가 있습니다. 바둑 보드에서 게임트리를 작성하면 가지가 무성한 나무가 생성되고, 결과적으로 조사해야 할 가지가 늘어난 만큼 수를 자세히 검색하기가 어려워지는 것입니다.
또한 바둑은 보드를 평가하는 휴리스틱 함수(heuristic function)를 작성하기 어렵다는 특징이 있습니다. 체스나 장기에서는 말의 종류에 따라 능력이 다르기 때문에 말의 가치도 달라집니다. 그러나 바둑은 모든 돌의 역할이 같습니다. 뿐만 아니라 체스나 장기는 마지막 지점의 우열이 그대로 게임의 승패로 이어지기 쉽지만, 바둑은 보드 전체가 평가 대상이라 일부의 평가로 보드 전체의 우열을 가리기 어렵다는 특징도 있습니다.
보드 평가가 어렵다는 점, 즉 평갓값의 신뢰가 낮다는 점은 알파베타 가지치기(Alpha-beta pruning)에 의한 탐색이 정확하게 기능하지 않는다는 것을 의미합니다. 이러한 단점들 때문에 AI 바둑 플레이어의 실력은 오랫동안 향상되지 못했습니다.
1.1 2006 ~ 2015년: 몬테카를로 트리 검색 방식
아마추어 수준에도 미치지 못했던 컴퓨터 바둑은 실반 젤리(Sylvain Gelly), 이자오 왕(Yizao Wang), 아자황(Aja Huang) 등에 의해 2006년에 도입된 몬테가를로 트리 탐색(MCTS; Monte Carlo Tree Search) 방식을 통해 비약적으로 발전하게 됩니다. 최초로 몬테카를로 방식(Monte Carlo method)을 사용한 'MOGO'라는 프로그램이 2008년 알려졌고, 이전까지 있었던 대다수 AI 바둑 프로그램들을 몬테 카를로 방식으로 전환하는 선구적 역할을 했습니다.
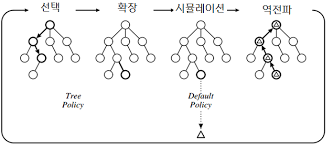
몬테카를로 방식에서는 휴리스틱 함수가 아닌 몬테카를로 트리 탐색, 즉 랜덤(random) 탐색으로 보드 평가가 이루어집니다. 몬테카를로 트리 탐색에서 어떤 보드에 대한 랜덤 탐색의 보드 평가는 다음과 같은 순서로 이루어집니다.
(1) 다음을 보드에서 시작해 적당한 횟수를 반복한다.
(1-1) 어떤 보드에서 시작해 착수 가능한 수를 차례차례 랜덤으로 선택해서 승부가 날 때까지 게임을 진행한다.
(1-2) 위의 (1-1)로 이기면 득점 1을 얻는다. 지면 득점은 0이 된다.
(2) 위 (1)을 반복하고 합계 득점을 반복한 횟수로 나누어 승률을 계산한다. 승률을 보드의 평가값으로 한다.
위 (1-1)에서는 규칙상 허용되는 수를 랜덤으로 선택해 게임을 진행합니다. 이처럼 승부가 날 때까지 게임을 진행하는 것을 플레이아웃(playout)이라고 하며, 어떤 보드에 대한 플레이아웃을 반복하면 그 보드가 평균적으로 어느 정도의 평갓값을 가지는지를 조사할 수 있다고 여깁니다. 이렇게 어떤 보드가 가진 여러 개 노드의 평갓값 중 가장 높은 값을 기준으로 다음 착수를 선택하는 것입니다. 이 방법이 몬테카를로 트리 탐색입니다. 이처럼 몬테카를로 트리 탐색에서는 플레이아웃의 보드 평가를 이용해 게임트리를 탐색합니다.
바둑처럼 휴리스틱 함수가 구성되기 힘든 문제에서도 몬테카를로 트리 탐색의 확률적 탐색으로 일정한 성능을 달성할 수 있다는 것이 증명되었습니다. 이러한 사실은 바둑의 AI플레이어를 구성하기 위해서만이 아나라, 탐색이 일반적인 문제 해결에 더욱 넓고 새로운 지침을 준다는 의미에서 중요한 돌파구가 되었습니다.
2. 알파고(AlphaGo) 이후 (2015년 ~)
몬테카를로 트리 탐색 이후 알파고(AlphaGo)가 등장하면서 AI 바둑 프레이어는 다시 한번 세대교체를 이루게 됩니다. 구글 딥마인드 알파고(AlphaGo)는 기존 몬테카를로 트리 탐색(MCTS) 방식에 컨볼루션 신경망(CNN)과 강화학습을 통한 딥러닝(deep learning) 방식이 적용되어 비약적인 발전을 이룬 인공지능 알고리즘입니다.
AI 바둑 플레이어는 몬테카를로 트리 탐색 덕에 아마추어 고단자 레벨까지 발전했으며, 딥러닝을 이용한 알파고는 최종적으로 세계 톱 레벨인 프로기사들을 이길 정도의 실력을 갖추게 된 것입니다.
2.1 알파고(AlphaGo)
알파고는 몬테카를로 트리 탐색에 심층 신경망(DNN)을 결합한 AI 바둑 플레이어입니다. 다시 말해 다음에 선택할 수를 추정하거나 보드의 형세를 판단하는 신경망을 작성하고, 이것을 이용해 몬테카를로 트리 탐색의 정밀도를 향상했습니다.
알파고에서 다음 수를 선택하는 신경망을 폴리시 네트워크(Policy Network)라 하고, 형세를 판단하는 신경망을 밸류 네트워크(Value Netwrok)라고 합니다.
알파고는 우선 인간의 기보 데이터를 이용해 지도학습을 한 후, 강화학습을 기초로 알파고끼리의 대국으로 학습을 진행합니다. 지도학습에서는 과거 인간의 대국에서 배운 네트워크를 학습시키고, 알파고끼리의 대국에서는 그것을 한층 더 개량한 학습을 진행하는 것입니다.
2.2 알파고 제로(AlphaGo Zero)
알파고에 이어서 출현한 알파고 제로(AlphaGo Zero)는 알파고의 신경망을 개량하고 폴리시 네트워크와 밸류 네트워크를 통합해서 강화한 것입니다. 그 결과 보드의 평가 능력이 향상되었고 몬테카를로 트리 탐색을 끝까지 진행하는 플레이아웃(playout)이 필요 없어졌습니다.
또한 알파고 제로는 알파고에서 이용한 인간의 기보(지도학습)를 이용하지 않고, 알파고끼리의 대국으로 학습을 진행합니다. 이런 틀에서 만들어진 알파고 제로는 알파고를 뛰어넘는 능력을 얻게 되었습니다.
2.3 알파 제로(Alpha Zero)
알파 제로(Alpha Zero)는 알파고 제로의 틀을 이용하여 바둑이 아닌 다른 게임에서도 다룰 수 있게 일반화한 것입니다.
알파 제로는 장기나 체스에서도 몬테카르로 트리 탐색과 딥러닝을 이용해 스스로 대국을 벌여 지식을 획득하는 장치가 효과적이라는 걸 증명했습니다.
2023.06.12 - [인공지능(AI; Artificial Intelligence)] - 인공지능과 게임 - 체스와 체커
'인공지능(AI)이란? - 기초 개념 및 이론' 카테고리의 다른 글
| 인공지능(AI)의 미래와 관련되는 몇 가지 개념들 (1) - 중국어 방, 프레임 문제 (0) | 2023.06.15 |
|---|---|
| 인공지능과 게임 - 장기 외 (0) | 2023.06.14 |
| 인공지능과 게임 - 체스와 체커 (0) | 2023.06.12 |
| 에이전트와 강화학습 (4) - 강화학습 (0) | 2023.06.11 |
| 에이전트와 강화학습 (3) - 로봇(Robot) (0) | 2023.06.09 |




댓글